At work this week I suggested an alternative to how we currently decouple code. I got asked the eminently reasonable question, "How is that way any better?" This post discusses the two approaches. Note that I think that the approach I favor can be improved upon, but this is a starting point.
The Problem
Imagine you have a Frobulator class. You use this object in many places in your code. However, you can foresee a situation where you might replace the Frobulator class because of a change in the underlying data source. If and when this occurs you don't want to have to go through your entire code base and change every occurrence of Frobulator to FrobulatorPrime. In short, you want to decouple your code base from the Frobulator object.
Solution 1

Create a
GenericFrobulator class. The
GenericFrobulator class has the exact same methods as the
Frobulator class. Its implementation is to have an instance of a
Frobulator and for every method to just redirect the call to the
Frobulator class. The rest of your code base uses the
GenericFrobulator object. If and when you replace the
Frobulator class, all you have to do is change the one class.
Cons
This requires writing a bunch of "dummy" code. I.e. one method for every method in Frobulator each of which is a single line of pass through code.
There is also a performance hit of the extra call - though realistically this is almost definitely negligible. Also, on errors or debugging stack traces will have an additional level in the stack, but this is only a minor level annoyance.
Pro
Successfully decouples the code base from the Frobulator object. Only one class has to change (in addition to the creation of the new FrobulatorPrime class) when a new implementation is used.
Solution 2
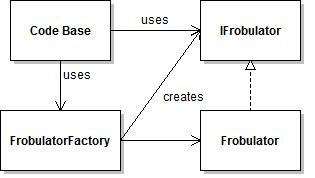
Create an
IFrobulator interface (we're working in C#, hence the 'I' prefix on interfaces) that has the same interfaces as the
Frobulator object, and make the
Frobulator class implement this interface. Create a
FrobulatorFactory class which has a single method which returns an
IFrobulator object. The implementation creates a
Frobulator object. The rest of the code base uses this
FrobulatorFactory class to create the
IFrobulator that it uses.
Cons
You have to create two additional classes (IFrobulator and FrobulatorFactory), one of which doesn't actually do anything.
Pros
It successfully decouples the code base from the Frobulator implementation.
Comparison
On the surface, these two approaches are pretty similar. They both require similar amounts of code. With the Interface approach you don't have to create "pass through" methods for every single method, but on the other hand you do have to create an extra class - the Factory class. Both approaches involve a similar amount of work to change out the Frobulator class -- create the FrobulatorPrime class, and either modify the FrobulatorFactory or the GenericFrobulator class.
Real Difference
The real benefit to the interface approach is the primary benefit to OO in general. Its not that it saves code, but rather it models your intent. By having an Interface and a Factory, it is explicit what the purpose of each class is. It is obvious that the Factory is for creating objects, and the Interface is for decoupling.
It also guards against new developers breaking the design. With the GenericFrobulator approach, it is always possible that down the road some developer will decide to insert logic (besides a simple call-through) into this class. Now all the decoupling power is lost. Interfaces (at least in languages like C# and Java) can't contain any code, so this can't happen.
The Interface method also supports a hybrid model. Imagine that you have a scenario where part of your code wants to use the Frobulator class, and part of it wants to use the FrobulatorPrime class. How would you do this with the GenericFrobulator approach? With the Interface and Factory approach, you can either create a new Factory, which some classes use, or you can have an additional Factory method/parameter to determine which object gets created. (or you could pass in the IFrobulator object and make it the calling code's responsibility).
I also feel that the Interface and Factory approach is closer to the real panacea of decoupling, though this is a fuzzier argument.
Failed Decoupling Goals
There are other goals of decoupling, that both of these approaches fail at. Both can be modified to potentially achieve them, though I feel that the Interface/Factory approach more naturally fits these modifications.
The first goal is to make it possible to change the Frobulator class out without having to make any changes to the code base. I.e. without having to change the Factory class or the GenericFrobulator class. An example of this is the java.db packages which you get via putting the right jar file in your classpath and using the right configuration string to get your db classes. (you are using a config file for this, right?)
The second goal is to be able to test the rest of your code base without having a Frobulator instance at all. Sometimes it is nice to be able to have a StubFrobulator class which creates test data, and use that to test the rest of the object. If your code is properly decoupled, this should not be difficult.
Summary
In short, I think the Interface and Factory approach is the better approach because it more directly describes the intent, more succinctly solves the problem, and is easier to modify to handle more advanced decoupling issues.
Is there yet a different way to decouple software? How do you do it?




